Jueves, 30 de abril de 2015
Actividad #16 • Investigar estrategias de procesamiento de consulta distribuida y optimización de consultas distribuidas.
Publicar Miércoles 6 de Mayo
Estrategias de procesamiento de consultas
En las BDD se tiene que considerar el procesamiento local de una consulta junto con el costo de transmisión de información al lugar en donde se solicitó la consulta.
El éxito creciente de la tecnología de bases de datos relacionales en el procesamiento de datos se debe, en parte, a la disponibilidad de lenguajes los cuales pueden mejorar significativamente el desarrollo de aplicaciones y la productividad del usuario final
Ocultando los detalles de bajo nivel acerca de la localización física de datos, los lenguajes de bases de datos relacionales permiten la expresión de consultas complejas en una forma concisa y simple.
Particularmente, para construir la respuesta a una consulta, el usuario no tiene que especificar de manera precisa el procedimiento que se debe seguir. Este procedimiento es llevado a cabo por un módulo del DBMS( Data Base Management System o Sistema Gestor de Base de Datos) llamado el procesador de consultas (query processor).
Dado que la ejecución de consultas es un aspecto crítico en el rendimiento de un DBMS, el procesamiento de consultas ha recibido una gran atención tanto para bases de datos centralizadas como distribuidas.
Sin embargo, el procesamiento de consultas es mucho más difícil en ambientes distribuidos que en centralizados, ya que existe un gran número de parámetros que afectan el rendimiento de las consultas
distribuidas.
Transformaciones equivalentes
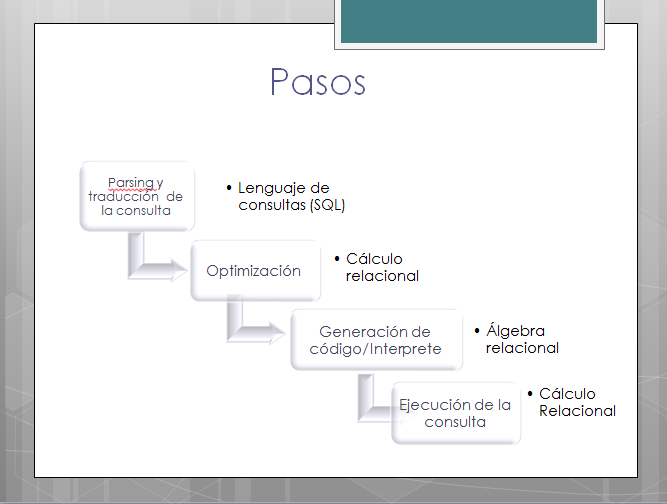
La función principal de un procesador de consultas relacionales es transformar una consulta en una especificación de alto nivel, típicamente en cálculo relacional, a una consulta equivalente en una especificación de bajo nivel, típicamente alguna variación del álgebra relacional
La consulta de bajo nivel implementa de hecho la estrategia de ejecución para la consulta. La transformación debe ser correcta y eficiente. Es correcta si la consulta de bajo nivel tiene la misma semántica que la consulta original, esto es, si ambas consultas producen el mismo resultado.
El mapeo bien definido que se conoce entre el cálculo relacional y el álgebra relacional hace que la correctitud de la transformación sea fácil de verificar. Sin embargo, producir una estrategia de ejecución eficiente es mucho más complicado. Una consulta en el cálculo relacional puede tener muchas transformaciones correctas y equivalentes en el álgebra relacional.
Ya que cada estrategia de ejecución equivalente puede conducir a consumos de recursos de cómputo muy diferentes, la dificultad más importante es seleccionar la estrategia de ejecución que minimiza el consumo de recursos.
Árboles de consultas
Existen distintos métodos para optimizar consultas relacionales, sin embargo el enfoque de optimización basada en costos combinado con heurísticas que permitan reducir el espacio de búsqueda de la solución es el método mayormente utilizado por los motores de base de datos relaciones de la actualidad, en todo caso, independiente del método elegido para optimizar la consulta, la salida de este proceso debe ser un plan de ejecución, el cual comúnmente es representado en su forma de árbol relacional.
Optimización de consultas distribuidas
El objetivo del procesamiento de consultas en un ambiente distribuido es transformar una consulta sobre una base de datos distribuida en una especificación de alto nivel a una estrategia de ejecución eficiente expresada en un lenguaje de bajo nivel sobre bases de datos locales.
Así, el problema de optimización de consultas es minimizar una función de costo tal que
Función de costo total = costo de I/O + costo de CPU + costo de comunicación
Los diferentes factores pueden tener pesos diferentes dependiendo del ambiente distribuido en el que se trabaje. Por ejemplo, en las redes de área amplia (WAN), normalmente el costo de comunicación domina dado que hay una velocidad de comunicación relativamente baja, los canales están saturados y el trabajo adicional requerido por los protocolos de comunicación es considerable. Así, los algoritmos diseñados para trabajar en una WAN, por lo general, ignoran los costos de CPU y de I/O. En redes de área local (LAN) el costo de comunicación no es tan dominante, así que se consideran los tres factores con pesos variables.
La complejidad de las operaciones del álgebra relacional
La complejidad de las operaciones del álgebra relacional afectan directamente su tiempo de ejecución y establecen algunos principios útiles al procesador de consultas. Esos principios pueden ayudar en elegir la estrategia de ejecución final. La forma más simple de definir la complejidad es en términos de la cardinalidad de las relaciones independientemente de los detalles de implementación tales como fragmentación y estructuras de almacenamiento. La Figura 4.3 presenta la complejidad de las operaciones unarias y binarias en el orden creciente de complejidad.
Operación Complejidad
La complejidad de las operaciones sugiere dos principios:
1. Dado que la complejidad es con base en las cardinalidades de las relaciones, las operaciones más selectivas que reducen las cardinalidades deben ser ejecutadas primero.
2. Las operaciones deben ser ordenadas en el orden de complejidad creciente de manera que el producto Cartesiano puede ser evitado o, al menos, ejecutado al final de la estrategia.
Es difícil evaluar y comparar procesadores de consultas para sistemas centralizados y distribuidos dado que ellos difieren en muchos aspectos. En esta sección se enumeran algunas características importantes de los procesadores de consultas que pueden ser usados como base para su comparación.
El problema de optimización de consultas es altamente demandante en tiempo de ejecución y, en el caso general, es un problema de la clase NP. Así existen dos estrategias para su solución: Búsqueda exhaustiva o el uso de heurísticas.
- Búsqueda exhaustiva
Los algoritmos de búsqueda exhaustiva tienen una complejidad combinatorial en el número de relaciones de la consulta. Obtienen la transformación óptima, pero sólo se aplican a consultas simples dado su tiempo de ejecución.
Granularidad de la optimización
Tiempo de optimización
Estadísticas
Nodos de Decisión
Topología de la Red
Fuentes de consulta
http://luisantoniosr.webcindario.com/BDD/bdd.html
https://cursos.aiu.edu/Base%20de%20Datos%20Distribuidas/pdf/Tema%203.pdf
- Uso de Heurísticas
Por otro lado, los algoritmos heurísticos obtienen solo aproximaciones a la transformación óptima pero lo hacen en un tiempo de ejecución razonable. Las heurísticas más directas a aplicar son el agrupamiento de expresiones comunes para evitar el cálculo repetido de las mismas, aplicar primero las operaciones de selección y proyección, reemplazar una junta por una serie de semijuntas y reordenar operaciones para reducir el tamaño de las relaciones intermedias.
Granularidad de la optimización
Existen dos alternativas: considerar sólo una consulta a la vez o tratar de optimizar múltiples consultas. La primera alternativa no considera el uso de resultados comunes intermedios. En el segundo caso puede obtener transformaciones eficientes si las consultas son similares. Sin embargo, el espacio de decisión es mucho más amplio lo que afecta grandemente el tiempo de ejecución de la optimización.
Tiempo de optimización
Una consulta puede ser optimizada en tiempos diferentes con relación a tiempo de ejecución de la consulta. La optimización se puede realizar de manera estática antes de ejecutar la consulta o de forma dinámica durante la ejecución de la consulta. La optimización estática se hace en tiempo de compilación de la consulta. Así, el costo de la optimización puede ser amortizada sobre múltiples ejecuciones de la misma consulta.
Durante la optimización de consultas dinámica la elección de la mejor operación siguiente se puede hacer basado en el conocimiento exacto de los resultados de las operaciones anteriores. Por tanto, se requiere tener estadísticas acerca del tamaño de los resultados intermedios para aplicar esta estrategia.
Un tercer enfoque, conocido como híbrido, utiliza básicamente un enfoque estático, pero se puede aplicar un enfoque dinámico cuando los tamaños de las relaciones estimados están alejados de los tamaños actuales.
Estadísticas
La efectividad de una optimización recae en las estadísticas de la base de datos. La optimización dinámica de consultas requiere de estadísticas para elegir las operaciones que deben realizarse primero. La optimización estática es aún más demandante ya que el tamaño de las relaciones intermedias también debe ser estimado basándose en estadísticas. En bases de datos distribuidas las estadísticas para optimización de consultas típicamente se relacionan a los fragmentos; la cardinalidad y el tamaño de los fragmentos son importantes así como el número de valores diferentes de los atributos. Para minimizar la probabilidad de error, estadísticas más detalladas tales como histogramas de valores de atributos se usan pagando un costo mayor por su manejo.
Nodos de Decisión
Cuando se utiliza la optimización estática, un solo nodo o varios de ellos pueden participar en la selección de la estrategia a ser aplicada para ejecutar la consulta. La mayoría de los sistemas utilizan un enfoque centralizado para la toma de decisiones en el cual un solo lugar decide la estrategia a ejecutar. Sin embargo, el proceso de decisión puede ser distribuido entre varios nodos los cuales participan en la elaboración de la mejor estrategia. El enfoque centralizado es simple, pero requiere tener conocimiento de la base de datos distribuida completa. El enfoque distribuido requiere solo de información local. Existen enfoques híbridos en donde un nodo determina una calendarización global de las operaciones de la estrategia y cada nodo optimiza las subconsultas locales.
Topología de la Red
Como se mencionó al principio, el tipo de red puede impactar severamente la función objetivo a optimizar para elegir la estrategia de ejecución. Por ejemplo, en redes de tipo WAN se sabe que en la función de costo el factor debido a las comunicaciones es dominante. Por lo tanto, se trata de crear una calendarización global basada en el costo de comunicación. A partir de ahí, se generan calendarizaciones locales de acuerdo a una optimización de consultas centralizada. En redes de tipo LAN el costo de comunicación no es tan dominante. Sin embargo, se puede tomar ventaja de la comunicación “broadcast” que existe comúnmente en este tipo de redes para optimizar el procesamiento de las operaciones junta. Por otra parte, se han desarrollado algoritmos especiales para topologías específicas, como por ejemplo, la topología de estrella.
Optimización Global de Consultas: El objetivo de esta capa es hallar una estrategia de ejecución para la consulta cercana a la óptima. La estrategia de ejecución para una consulta distribuida puede ser descrita con los operadores del álgebra relacional y con primitivas de comunicación para transferir datos entre nodos. Para encontrar una buena transformación se consideran las características de los fragmentos, tales como, sus cardinalidades.
Optimización Local de Consultas: El trabajo de la última capa se efectúa en todos los nodos con fragmentos involucrados en la consulta. Cada subconsulta que se ejecuta en un nodo, llamada consulta local, es optimizada usando el esquema local del nodo. Hasta este momento, se pueden eligen los algoritmos para realizar las operaciones relacionales. La optimización local utiliza los algoritmos de sistemas centralizados.
Fuentes de consulta
http://luisantoniosr.webcindario.com/BDD/bdd.html
https://cursos.aiu.edu/Base%20de%20Datos%20Distribuidas/pdf/Tema%203.pdf